

利用 Wolfram 语言构建的神经网络促进学生的化学学习 利用 Wolfram 语言构建的神经网络促进学生的化学学习 我参加了2020 年 Wolfram 神经网络训练营,它启发我将数据科学和机器学习的元素融入我的课程中。机器学习的辅助函数使实验和向学生介绍此类应用程序变得非常容易。我们选择通常引入神经网络和机器学习主题的图像识别和分类问题。 然而,我很快对缺乏面向化学的图像数据集这一事实感到震惊,并在使用了修改后的国家标准与技术研究所 ( MNIST ) 手写数据集示例后,决定创建这种类型的数据集。目标是为学生提供端到端的数据科学项目体验,从创建数据到执行高级机器学习练习的最后一步。因此,该项目创建了一组化学实验室中常见的玻璃器皿图像,目的是构建我们自己的物体识别示例。 方法 以下步骤概述了如何收集每件玻璃器皿的图片: 1. 为空的和装满水的玻璃器皿拍照。 2. 用不同颜色的溶液填充玻璃器皿,使其达到不同的水平,例如,250 毫升锥形瓶将被填充到不同的体积容量。 3. 提供各种背景,例如,一些玻璃器皿被放置在实验室工作台或升高的表面上以提供不同的背景。 4. 整理 Google Drive 上共享文件夹中的所有图片。学生将手机中的图片上传到共享云端硬盘。 分类问题中的项目类别以及每个类别中的项目数量是: 这幅拼贴画包含 17 种不同类型的实验室设备,每种设备各一张图片。展示移液器图片存在一些困难。在图片中似乎很难看到 5 mL 移液管,因此我们使用白色或黄色纸张背景来突出显示它们。当然,标签还有一些其他问题。一些玻璃器皿通常被悬挂使用,例如滴定管和分液漏斗。 可以装满液体的测定体积的玻璃器皿比数据集中的其他物品拥有更多的图片。这组烧杯图像说明了多样性: 这里重要的一点是数据收集包括多种变化:照明条件、对物体的聚焦、手机质量、图片预设和每个标签的各种图像。 数据集增强 由于数据集中的图像数量较少,并且不同类别之间的图像数量存在差异,我们认为通过对图片进行一些图像修改来增加样本空间是明智的。我们利用 ImageEffect 选项将样本大小增加了 19 倍: 使用 Blur 函数对图像进行模糊处理,并随机选择应用模糊的像素半径。还使用适当命名的函数将图像修改为更亮或更暗。接下来,收集所有这些图像并从左到右翻转。最后的操作在 –10 到 10 度之间随机旋转所有图像。 以下是对锥形烧瓶标签中的单个图片进行这些操作的结果: 这一系列操作对单个烧杯类图像的效果如下所示: 现在,我们将分别从烧杯、平底烧瓶和洗瓶类中选择一张图像来表示图像增强效果: 图像集增强产生了 6,365 张图像。然后我们决定使用它作为我们的数据集,用于训练和测试 Wolfram 神经网络存储库中可用的各种预训练神经网络。 神经网络 我们决定评估图像识别领域四个著名的预训练神经网络的性能。以下是这些神经网络的来源、层数和参数的摘要: 数据导入和组织 我们拆分数据集以使用 80% 的数据作为训练集,剩余的 20% 作为测试集。我们导入了训练集和测试集,并使用四种变体进行了分类性能的训练和评估: 1. 全彩图像 2. 使用前面描述的图像增强模块增强数据集的全彩图像 3.来自全彩色图像的灰度图像 4. 使用前面描述的图像增强模块增强数据集的灰度图像 让我们看一些训练和测试集的例子: 80-20 分割后,以下是训练和测试集中的总图像: 培训和结果 以下步骤用于对从 Wolfram 神经网络知识库获得的预训练重置模型进行网络手术: 1.从预训练网络中移除线性层。 2.移除已训练网络的最终分类层,并用此分类任务替换它们: 在本例中,LinearLayer 和 SoftmaxLayer 函数已被删除,并创建了一个由预训练网络、线性层和 softmax 层组成的新网络: 在最后的分类器步骤中,LinearLayer 采用一个整数参数作为类的数量。实验室玻璃器皿鉴定实验类数量如下:  附加了一个未初始化的 LinearLayer 和一个 SoftmaxLayer 以创建最终网络。带有实验室玻璃器皿指定标签的 NetDecoder 被用于根据网络的输出推断类的名称: 在这里,我们将在 MaxTrainingRounds 设置为 5 的情况下执行训练。训练在配备 NVIDIA Quadro M2000M GPU 的笔记本电脑上大约五分钟内完成。对于迁移学习,除了最终分类器层之外的所有层都保持冻结: 可以从经过训练的网络中获得各种属性。我们在这里列出一些:  分类性能 经过训练的网络可以直接与 ClassifierMeasurements 函数一起使用,以获得各种性能指标: 获得训练网络在测试集上的整体准确率: “ ConfusionMatrixPlot ”是一种很好的绘图技术,可以可视化分类的正确性。非对角线项是错误分类的示例: 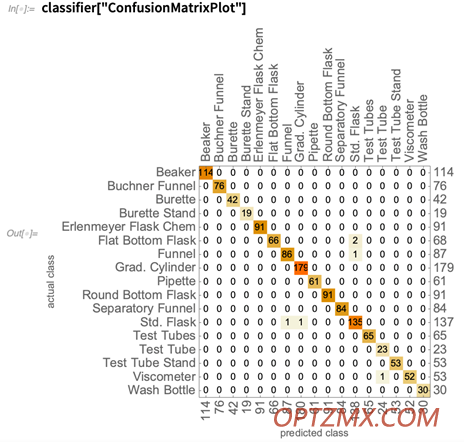 以下是网络错误分类的六个错误中的前五个:  从混淆矩阵中可以清楚地看出误分类的频率很低。量筒在测试的 179 个样品中只有一次被错误分类为标准烧瓶。计算成本极低的高精度对学生来说是一个启示。另一个引人注目的例子是具有完美精确度和召回率的布氏漏斗分类。测试集(23)中图像数量最少的试管类也显示出完美的召回率:  结果概览 按照前面描述的过程,我们在实验室图像的四个变体上测试了四个神经网络。 对于未增强的数据集,训练期间的验证错误最初非常高。经过几轮训练后,两个数据集都产生了准确度更高的训练网络: 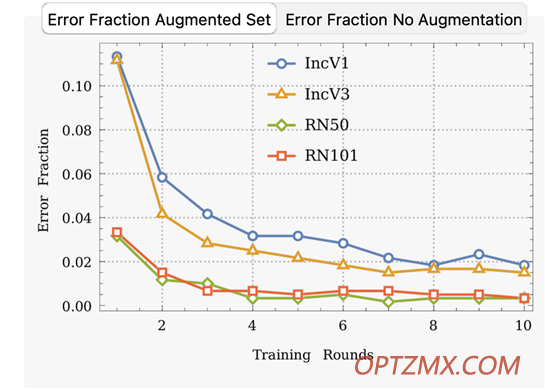 下图显示了所有四个训练网络在四个数据集变体中的每一个的训练时间和准确性。不出所料,与未增强的数据集相比,扩大的数据集需要更长的时间来训练并提供更高的准确性。ResNet-50 和 ResNet-101 网络都在灰度图像和全彩色图像之间提供相似的分类精度:  教学理念与结论 Zenodo 上提供了用于网络训练和数据分析的数据集图像和示例笔记本。这应该使其他教师能够完整地使用该项目或使用其数据设计其他项目。一种简单的扩展是添加不同的玻璃器皿图像并研究分类性能。另一个有趣且可能更高级的应用是识别玻璃器皿上标注体积的文字,尤其是烧杯或锥形烧瓶上的文字。该项目还为非计算机科学背景的学生提供了有关深度学习和预训练神经网络力量的实践经验 致谢 我感谢瓦格纳学院 (Wagner College) 科学计算导论课程中的学生。我还要感谢 Tuseeta Banerjee 博士和 Mads Bahrami 博士受邀撰写这篇博文,感谢 Wolfram 博客团队对本文发表的支持。 Arun Sharma 是纽约市瓦格纳学院的化学副教授。他的研究和教学兴趣包括计算化学、机器学习以及将计算融入本科化学实验的各个层次。他领导着一个由本科生组成的研究小组,负责各种项目,包括分子动力学模拟、量子化学计算和机器学习在化学问题中的应用。美国国家科学基金会和美国化学学会石油研究基金对他的研究小组给予了支持。 相关刊物 [1] AK Sharma,“实验室玻璃器皿识别:科学学生的监督机器学习示例” ,计算科学教育杂志,12 (1),2021 年第 8-15 页。doi.org/10.22369/issn.2153-4136/12/1/2。 [2] AK Sharma,“通过神经网络训练和识别玻璃器皿的玻璃器皿图像和代码示例”,Zenodo(2021 年 5 月 6 日)。doi.org/10.5281/zenodo.4019356。 购买软件/免费试用 【13.2.1 中英文 Wolfram 软件】请评论区留言
分享到:
|
